CLEAVER: Hierarchical Text Partitioning & Analysis
A Novel Approach to Semantic Parsing and Text Analysis
Abstract
CLEAVER introduces a novel, hierarchical approach to English text categorization and partitioning. Focusing on independent semantic value, it distinguishes itself from traditional syntactic parsers by offering an expansive range of linguistic units for text analysis. By identifying the largest meaningful span of tokens within a text, CLEAVER's hierarchical framework provides a novel system for textual segmentation to be used in text generation and analysis.
Background
Recent years have seen Transformer-based Neural Networks replace rule-based, statistical models in Natural Language Processing (NLP) and semantic parsing. Despite these advancements, there remains no comprehensive framework for semantic analysis, making it difficult to translate machine learning advancements to educational technologies. Traditional syntactic parsers provide limited insight into the semantic structure of text, and researchers seeking semantic analysis often construct custom partitioning systems or use specialized transformer models.
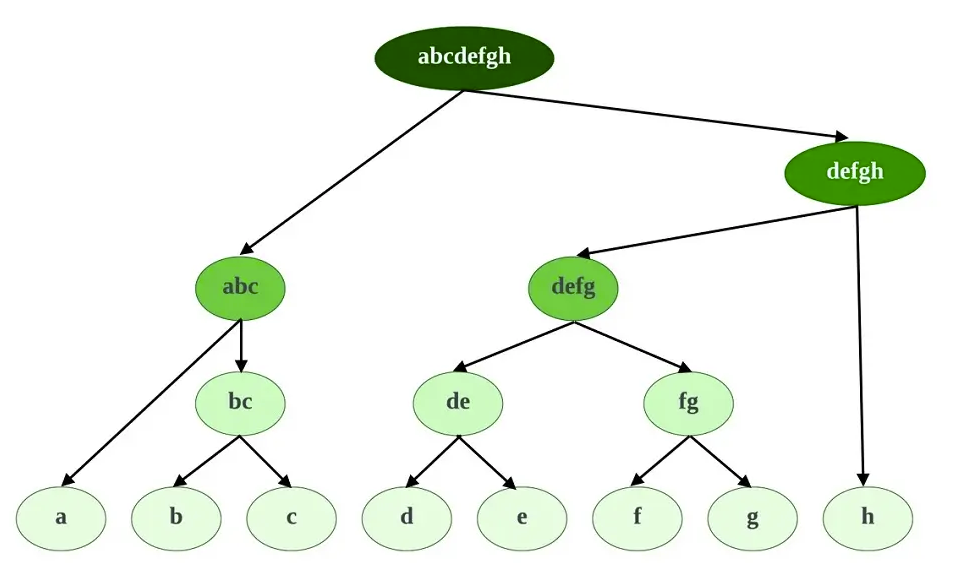
Figure 1: Visualization of CLEAVER's hierarchical text partitioning approach
Importance
CLEAVER addresses several critical limitations in current NLP approaches:
- High computational costs of transformer-based models (ranging from $80,000 to $1.6 million for Small Language Models)
- Inaccessibility of word mappings in large models, commonly referred to as "black boxes"
- Less robust text generative control in smaller models
- Lack of semantic framework for text prompting and generation
By providing a hierarchical semantic partitioning system, CLEAVER enables better analysis of text data itself, allowing language models to be specialized for specific writing tasks such as analyzing semantic patterns in student writing or argumentation.
Technical Implementation
CLEAVER draws from the principle of compositionality in Compositional Semantics, by which the aggregate meaning of a phrase is determined by the composition of its subphrases. The system includes:
- Corpus of 30 unique semantic idea-units: From Compound-Complex Sentences down to individual Linking Phrases
- Hierarchical partitioning structure: Retains the largest possible construction of semantic meaning at each level of analysis
- Flexible interpretation framework: Allows for multiple interpretations of a span of text, including traditional Constituency Parsing
- Context-dependent text analysis: Enables discovery of unique relationships and patterns between semantic units
The system begins partitioning at the highest level of compositional meaning (compound-complex sentences) and continues down to simple sentences, noun complexes, and eventually the word-token level.
CLEAVER Semantic Idea-Units
Figure 2: Hierarchical structure of text partitioning in CLEAVER
| Attribute (Abbreviation) | Description |
|---|---|
| Compound-Complex Sentence (CCS) | Contains multiple Nominal Subjects (SH), indefinite Verb-Object units (SB), and indefinite Asides (A). |
| Compound Sentence (CS) | Contains multiple Nominal Subjects (SH), indefinite Verb-Object units (SB), and no Asides (A). |
| Complex Sentence (XS) | Contains a singular Nominal Subjects (SH), indefinite Verb-Object units (SB), and indefinite Asides (A). |
| Aside (A) | Extraneous information signified by surrounding punctuation. |
| Sentence (S) | Composition of a Structural Phrase, Nominal Subject (SH), and an indefinite number of Verb-Object units. |
| Structural Phrase (SP) | Adjectival, Adverbial, Prepositional, or Nominal information that precedes the Nominal Subject (SH). |
| Simple Sentence (SS) | Composition of one Nominal Subject (SH) and an indefinite number of Verb-Object units. |
| Sentence Head (SH) | Nominal Subject of a Simple Sentence. |
| Sentence Body (SB) | Containing at least one Verb, the total span of Verb-Object units within a Simple Sentence. |
Table 1: Core semantic idea-units in CLEAVER's partitioning system (showing 9 of 30 total units)
Integration with Lexical-Semantic Resources
Future development of CLEAVER will include integration with cognitive and psychological word categories from established lexical resources to enhance semantic analysis capabilities:
- WordNet Integration: Mapping partitioned text units to WordNet's extensive lexical database to identify semantic relationships and hierarchies
- VerbNet Enhancement: Implementing thematic role assignments to identify agents, patients, themes, and instruments within partitioned units
- Psychological Database Applications: Incorporating affective norms and psycholinguistic variables from resources like ANEW
- LIWC Integration: Applying psychological and cognitive categories to analyze emotional, cognitive, and structural components of text
This integration will enable CLEAVER to not only partition text according to its hierarchical semantic structure but also to estimate underlying psychological and cognitive dimensions of the text, bridging computational linguistics with cognitive psychology.
Key Conclusions
- CLEAVER offers a novel framework for continued research in optimizing small transformer-based models for text generation and analysis.
- By segmenting texts into attributable semantic categories, CLEAVER determines probabilistic relationships at the semantic level, increasing statistical relationships between words and phrases not typically seen in limited training datasets.
- This approach increases compositional variability and prompting control in text generation by allowing models to select from semantic structures before generating text.
- CLEAVER negates statistical bias within training sets and strengthens relationships between semantic categories, forcing machines to "think" beyond words and expand acceptable grammars.
- The system provides researchers greater control over text composition in generative models and enables specialized analysis of specific writing tasks.
- The integration with cognitive and psychological lexical resources will further enhance CLEAVER's capability to constrain and estimate semantic meaning, bridging computational linguistics with cognitive psychology.
Further validation of CLEAVER's utility within text generative models and analysis is needed through continued research in text prompting and categorization.